
Introduction and Background
Traditionally training in surgical specialties relied on apprenticeship where experience and expertise was gained by working under a senior experienced surgeon. Such training would often continue for a prolonged period until the trainee felt comfortable and confident in carrying out the procedure on their own. In the absence of a formal structured training programme, graduation from an apprenticeship to a more senior grade would predominantly depend on the opinion of the supervising trainer. In 1889 William Stewart Halstead had formulated the old adage, ‘see one, do one, teach one’ which was based on the quantum and intensity of workload and the trainee doctor personally attending the workplace to care for and treat the real patient.1 In many countries uninfluenced by the European Working Time Directive, this system of learning remains the mainstay of training, particularly in surgical disciplines where manual dexterity and skills may take a relatively longer time to master.
In the last two- or three-decades laparoscopic surgery has become widely used and has replaced open surgical procedures. This has given rise to novel challenges in education and training of new surgeons. These challenges include the use of long rigid instruments which are much less flexible, have reduced range of movement compared to hands and fingers, amplify movement and tremor, lack the tactile sensation and also make it difficult to perceive depth and carry out three-dimensional movement.
Restricted working hours as a result of European working time directive, increased demands due to revised surgical waiting list targets, rising cost of operating time on surgical operating lists, heightened public awareness leading to concerns being raised about the ethics of basic surgical training on real patients has led to rethinking of the way surgical training is provided. Bridges and Diamond estimates that financial cost of utilising real life operating room time for training surgical residents in United States is $53 million per year.2 Scott et al estimate that the cost of training in the Guided Endoscopic Module (Karl Storz Endoscopy, Culver City, CA) varies from $215,000 to $285,000, depending on the quality of video-imaging equipment installed.3 At the University of Texas South-Western Medical Center, the cost of training residents using a video-trainer is $270 per graduating resident.3 This value stands in contrast to the cost estimate by Bridges and Diamond at the University of Tennessee Medical Center of using operating room time to train residents for approximately $48,000 per graduating resident.2 Therefore, training outside of the operating room using simulation-based training (SBT), although expensive, seems cost effective.
However, assessment of cost effectiveness of simulation-based training (SBT) is very difficult and complex to undertake mainly because of the uncertainties associated with assessing cost benefits that arise from learners being able to transfer their skills to real life practice and considering patient outcomes.4,5
In the published literature there is no clear and definitive indication of cost analysis of SBT in surgical practice.
The above-mentioned factors have produced changes in surgical training curriculum and methods of assessment of training giving rise to surgical skills training programmes and simulation laboratories. Many researchers believe that simulation-based education can improve surgical skills in both simulation laboratory and in real life surgical operation.3,6–16 However, many of the assessments following simulation-based training has been undertaken either on cadavers or animal models.11,17–19 Some authors assessed transfer of training and measured transfer effectiveness ratio in their randomized controlled trial but on scrutiny it became obvious that they had assessed the outcome of their intervention by trainee performance on cadavers.20
We excluded internal medicine subjects and diagnostic endoscopies because we wanted to focus on skills transfer in surgical procedures where manual dexterity and expert operative competence comes in to reckoning. Moreover, complexities in surgical care are relatively more, the nature of treatment mostly definitive and irreversible and chances of life changing error higher. Some authors state that amongst reported errors about half the adverse events were surgical in nature.21,22
Despite advances in structured surgical training, technical proficiency remains poorly evaluated. In present day surgical training programmes at no point is there a compulsion for objective assessment of technical skills. Evaluation of competence is very prone to subjectivity and bias in assessment. Only very few studies have been carried out to show skills transfer from simulation room to the real-life operating scenario.
Aims and Objectives
This systematic review of the randomised trials aims to find out if such resource worthy simulation-based training leads to any benefits in actual real life surgical practice.
From practical personal experience about assessment of trainees the authors were wary of the variation in nature and type of assessment applied and their subjectivity. We aimed to find any difference in speed or duration of surgical procedure, and any identifiable improvement in assessment of technical skills by utilising any of the commonly used assessment tools, for example, Objective Structured Assessment of Technical Skills (OSATS). Our target group were learners who underwent SBT followed by operating in the real-life scenario. The authors also wanted to identify any possibility of bias in reporting as well as the statistical power of the respective trials.
Methodology
Because of the rapid development and advancement in technology in simulation-based education in the present millennium, we decided to restrict our review to the published literature between 2000 and 2020. We excluded trials where participants were medical students because we wanted to include participants who were committed to a career in surgery and hence had the motivation and desire to improve and do better in their career.
Literature Search
A search of the published literature was carried out using Medical Subject Headings (MeSH), ‘high fidelity simulation training’, ‘simulation training’, ‘surgical procedures’, ‘surgery’, ‘general surgery’, ‘clinical competence’, ‘clinical skill’, ‘fidelity’, ‘realism’, ‘reality’, ‘accuracy’. The databases searched were, OVID (Embase, American Psychological Association Psycinfo, Medline), Pubmed, Cumulative Index to Nursing and Allied Health Literature (CINAHL), and Cochrane Library. Duplicates were excluded in each database.
The reference list in the latest Cochrane database systematic review (CDSR) ‘Laparoscopic surgical box model training for surgical trainees with limited prior laparoscopic experience’ was also searched for relevant papers for this systematic review.23
The International Standard Randomised Controlled Trial Number (ISRCTN) was searched for any studies registered that conformed to criteria for our systematic review.
A publication in Cochrane Database of Systematic Reviews by Gurusamy KS, Nagendran M, Toon CD, Davidson BR, 2014, Issue 3. Art No.CD01047823 and the other nineteen papers which were finally selected were searched for cross reference. Reference list in these publications was searched and abstracts were reviewed in twenty-four selected papers. Of these fourteen papers were short listed. Of these fourteen papers, two abstracts were conference papers which could not be obtained. There was no response from these two authors following our e-mail communication.
So, twelve papers were identified and selected from cross reference of this Cochrane Systematic Review and those finally selected nineteen papers. One of these papers was a review essay, and two papers were about non-randomized trial. So, nine papers were selected from these cross references.
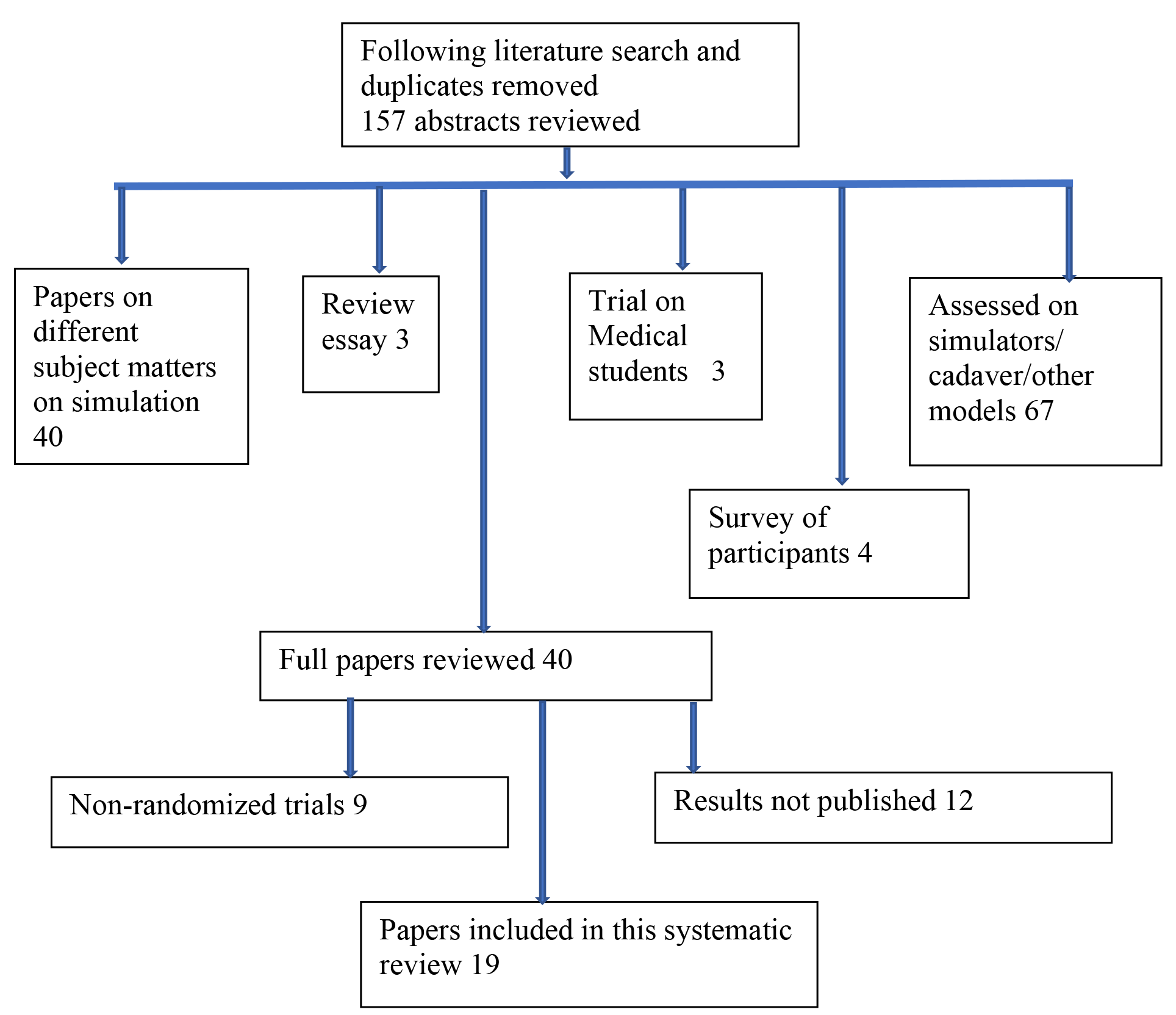
A total of 157 abstracts were reviewed by BK, RR and GK
Nineteen papers were finally selected for this systematic review (n=19).
Data Extraction and Analysis
BK extracted all the data from the nineteen included trials and was checked by RR using standard data extraction tables agreed and produced by the authors. Each included trial was scrutinized and critically appraised for its quality and details. The quality assessment of these trials included, method of reporting, methods of randomisation, sample sizes, allocation concealment, blinding of assessors and interrater reliability of assessors.
Pooling of data from these nineteen trials was not possible due to the heterogeneity of methods used and the variety of outcome measures used.
A total of 157 abstracts were reviewed by BK, RR and GK
Nineteen papers were finally selected for this systematic review (n=19).
_flow_diagram_s.png)
Results
Ethics approval and consent
Fifteen out of the nineteen trials declared obtaining ethics approval from their respective organisational department and consent from the participants. In their published paper, Banks et al,24 Larsen et al,25 and Seymour et al,6 did not explicitly state about ethics approval but their trials were registered and as such would have included ethics approval. Zandejas et al26 stated that their trial was found to be exempt from requirement of ethics approval by the Mayo Clinic Institutional Review Board, Rochester, MN, USA. All their trial participants gave consent to be part of the trial.
Randomization, blinding and type of assessment
Authors of all the included trials declared having undertaken random allocation of participants in to SBT and Control groups. Fourteen of nineteen authors also stated the exact method of randomisation. Some of the authors, while making it clear that they undertook randomization, didn’t actually mention the exact methods that they followed.6,27–30
With the exception of one trial by Gala et al, rest of the assessors were blinded to the randomization status of the participants.31 In another trial by Hogle et al, assessors present in operating room (OR) were unblinded but in the same trial video assessors were blinded to the training status of participants.32 In ten of the nineteen trials assessors were present in OR and in the remaining trials assessment was performed on video recordings of the operative procedures carried out by participants. In two of the assessments in OR there was additional assessment of video recording of the same procedure by other assessors.28,32 This data is presented in Tables 3-10.
Surgical procedures tested, type of simulator used and comparator
The terminologies, ‘trainees’ or ‘participants’ has been used to refer to individuals who were the test subjects in the trials included in this systematic review. The group, which received focussed or targeted training have been referred to as the Simulation-based training (SBT) group. The comparator group has been referred to as the Control group who either received no SBT or had access to SBT but without any formalized targeted plan or predefined skills targets to be achieved.
Seven RCT s tested skills transfer in laparoscopic cholecystectomy procedures, four RCT s tested skills transfer in laparoscopic salpingectomy, three in laparoscopic total extraperitoneal hernia repair, two each in laparoscopic tubal ligation and knee arthroscopy and one for intracorporeal suturing and knot tying in a laparoscopic Nissen fundoplication procedure. All these RCT s compared surgical performance of participants who underwent SBT with the control group. There was a wide variation of simulators used to train the participants in the different trials.
LapSim Virtual Reality Simulator was used in four trials.25,28,32,33 Minimally Invasive Surgical Trainer Virtual Reality (MIST VR) was used in three trials,6,9,30 and standard laparoscopic simulator was used in two trials24,31
Video laparoscopy training was used in two trials.27,34 The remaining trials used one of the following simulators: ArthroSim Virtual Reality Simulator, moulded rubber hernia simulator, McGill Laparoscopic Inguinal Hernia Simulator, Video and porcine cadaver, dry knee arthroscopy model, Box trainer and Virtual Reality Simulator, Fundamentals of laparoscopic surgery programme and Web-based Mastery Learning. This is shown in Table 2.
As shown in Table 2, in vast majority of trials, participants in the comparator group or controls were not allowed access to SBT. Only in four of the nineteen trials the participants randomized to Control group were allowed to practice on simulators although their practice was not formalised, was not supervised nor did they have any predefined targets to achieve before their skills assessment27,28,30,35
Baseline assessment of participants of simulation-based training group and control group
In all the nineteen trials, a baseline assessment of the SBT group and Control group was carried out. Kurashima et al. declared that their control group participants had slightly more overall laparoscopic experience than SBT group at baseline assessment (p=0.045).36 Remaining characteristics of the two groups were not significantly different (p>0.05). In the remaining eighteen trials the demographic characteristics, relevant operative skill and past experience in the relevant surgical procedure were similar, and not statistically different amongst the SBT and Control groups (p >0.05). In the trials where a mixture of junior and senior residents was recruited, the authors carried out block randomization so that the composition and mixture of each group, SBT and Controls, were similar.36,37 Sroka et al state that they carried out a baseline assessment of their recruited participants using GOALS score and excluded from randomization all those participants who scored more than 15.38
Duration of study and time to assessment
The elapsed time after training was completed and before the assessment was undertaken was not very clear in all the trials. In almost all trials the final assessment seems to have taken place within a short time after the training of the SBT group participants was completed. The maximum duration to assessment appears to be 316 days but this was almost similar in both the SBT group and the Control group in this particular trial.31 In all trials, the assessment on real patients was undertaken after the predefined proficiency was attained by the participants in the SBT group. In most trials, the duration of study and time to assessment was dictated by the residency rotation programme ^24, 30, 34, 36,38, 39,^ . Table 2 demonstrates the time utilised and duration to assessment of competence.
Experience and type of participants
In fifteen of the nineteen trials in this systematic review, the participants were postgraduate residents ranging from year 1 to year 4 without any previous experience of the operative procedure that was being assessed. Kurashima et al, Van Sickle et al and Zandejas had recruited some postgraduate years 5 or 6 but these residents did not have prior experience of the operation being tested.26,30,36 Grantcharov recruited sixteen surgeons for their trial on laparoscopic cholecystectomy, but these surgeons had ‘limited’ experience in this procedure and their SBT group matched with their controls.9
Coleman et al found that in their trial the improvement of performance in laparoscopic partial salpingectomy was most striking in postgraduate year 3 residents compared to postgraduate year 4 residents.27
Type of operative cases and role of Supervisor and Assessor
In all trials, simple and uncomplicated patients were chosen for operative assessment. When any complication was detected on the operating table, those cases or participants were excluded from trial. In vast majority of the trials, authors have not mentioned about any instance of take-over by the supervisor or experienced assistant. Ahlberg et al mentions that in their trial, three operations had to be converted from planned laparoscopic cholecystectomy to open surgical procedure.33 Cannon et al mentions that in their trial if the resident participant took more than 25 minutes then the attending supervisor took over the operative procedure and the unfinished task in that instance was allocated a score of zero.39 In many of the trials, an experienced surgeon supervised and assisted in the surgical procedure but the assessment and scoring for the trial was done by an independent blinded assessor.9,25,28,29,32,34,36,40
Outcome measures used and findings
Different outcome measures were used by the trial authors for assessment of transfer of skills from SBT to real life practice, as shown in Tables 3-10. In these tables, the group of participants who had simulation-based training (SBT) has been referred to as SBT group and the comparator group who did not have any targeted simulation training has been referred to as the Control group or C group.
Ahlberg,33 Seymour6 and Van Sickle30 evaluated the participant’s performance using mean number of errors, surgical time, and other measures like conversion of laparoscopic procedure to open surgery and excess needle manipulation. The group of trainees who had SBE made significantly smaller number of errors (p= <0.05). Surgical time was also significantly less in the SBT group (p=<0.05). Conversion of laparoscopic procedure to open surgical procedure was required thrice in the Control group compared to none in the SBT group.33 Van Sickle found that the SBT group in their trial carried out significantly less needle manipulation than their controls (p= <0.05).30 Details are presented in Table 3.
As shown in Table 4, some authors used one or another type of Global Rating Scale (GRS) on its own to assess transfer of skills to operation on real life patient.27,32,34,36,38 These GRS were devised by different authors as indicated in Table 4. The SBT group performed significantly better (p= <0.05) than the control group in all but one of these trials. Hogle found that in their trial, in the domains of depth perception, bimanual dexterity, efficiency, tissue handling and autonomy, there was no significant difference between the performance of SBT group and Control group, although the SBT group fared better than the Control group (p= 0.55 to 0.99).32
Banks, as shown in Table 5, used a 25-point Task specific check list, a GRS and pass rate to assess the participants in their trial. In all these three outcomes measures their SBE group performed significantly better than their Control group (p= 0.002, 0.003 and 0.003 respectively)24
Cannon et al, in their trial of diagnostic knee arthroscopy used a procedural checklist, visualization scale, probing scale and a global rating to assess performance of participants in their trial. In all these outcome measures, except the visualisation scale, their SBT group were found to be significantly better that their control group (p= 0.031, p=0.34, p= 0.016, p=0.061 respectively). In the visualisation scale the SBE group performed better but not significantly so.39 Table 6 shows the findings of this trial.
Table 7 demonstrates the trial results of those authors who used Objective Structured Assessment of Technical Skills (OSATS) as the outcome measure to compare SBT group with their control group.25,31,35,37 The OSATS tools used in these trials were devised by different authors as shown in table 8. In all these trails the SBE group performed significantly better than the control group (p=< 0.05)
Gauger,28 Hamilton29 and Zandejas,26 used Global Operative Assessment of Laparoscopic Skills (GOALS) to assess and evaluate the performance of participants in their trials. The authors of GOALS tool, which these authors used have been mentioned in Table 8. The SBT group in all three trials performed much better than the Control group.
However, the improvement seen by Gauger et al was not statistically significant (Overall competence p= 0.228 and task completion score, p=0.345).28 They found significantly lower number of errors in their SBT group. In the trials by Hamilton29 and Zandejas,26 GAOLS score was significantly better in the SBT group (p= < 0.05). In addition, instrument knowledge and handling were significantly better in Hamilton’s trial.
The trial by Zandejas,26 was the only one amongst the nineteen trials included in this systematic review, where patient related outcomes were investigated. Apart from significantly better operative time (p=0.0001), Zandejas found that intraoperative complications, postoperative complications and overnight stay were significantly less likely in the SBT group (p= < 0.05).
Grantcharov found that their SBT group performed significantly better than their control group in the outcomes they studied, that is, economy of movement (p=0.003), duration of procedure (p=0.021) and error score (p= 0.003).9 Table 10 shows the findings.
The trial by Roberts et al was novel in that they used wireless elbow worn motion sensors to surgical performance objectively.40 Their primary outcome measure for diagnostic knee arthroscopy was number of hand movements where the SBT group performed significantly better than the control group (p= < 0.001). For their secondary outcomes (minor movements, smoothness and time taken) the SBE group was significantly better than the control group (p= < 0.001). Average time taken by SBT group was 320 seconds versus 573 seconds by the controls (p= < 0.001).
Comfort level of participants in the trials
In four of the nineteen trials authors looked at comfort levels or perception of participants involved in the trial. Coleman (2002) found that both their SBT and Control groups expressed lower than average comfort levels pre-test and post-test.27 The pretest scores for SBT group were 12 versus 13.5 for controls and post-test scores were 16 versus 17 respectively. There was statistically significant improvement in the post test comfort levels (p=0.001). There was no difference between the SBT and control groups. Within the SBT group there was a weak association between self-perception and operative evaluation by Global Surgical Assessment Tool (GSAT).
Patel (2016) found that in their control group there was no change in 8 of the 10 subjective comfort levels.37 In their SBT group there was an improved sense of comfort with anatomy knowledge (p=0.02), surgical steps (p=0.004), double handed surgical technique (p=0.04), knowledge about energy (p=0.002), understanding of the risk-benefit of the procedure (p=0.04). They also perceived benefit of viewing procedural video and SBT before performing the real operation.
In their trial, Scott (2000) found that 3 of 13 of their control group participants and 5 of 9 SBT group participants felt comfortable with their laparoscopy skills.34 After completion of the study, their perception had improved to 6 of 13 and 8 of 9 in the respective groups. Amongst those who didn’t feel comfortable 3 of 10 controls and 3 of 4 SBT group participants perceived a sense of comfort after the study (p= 0.175). In the SBT group all nine participants felt that the video trainer was useful and eight of the nine felt that the training had enhanced their skills during real life operating.
Van Sickle (2008) reported that several of their participants admitted to feeling nervous in the high-stake environment instituted for the assessment in the trial.30
Meta-analyses
Five meta-analyses were conducted for mean error rates (k = 5), surgical time (k = 7), OSATS (k = 4), GRS (k = 4), and GOALS (k = 4). All meta-analyses were conducted with the MAJOR package (v 1.2.1; Hamilton, 2021) in Jamovi (v 2.2.1; The Jamovi Project, 2021).41 Standardised mean differences were extracted for all outcome variables given the between-study heterogeneity in procedures and operationalisation of outcomes. Standardised mean differences were extracted for all outcome variables given the between-study heterogeneity in procedures and operationalisation of outcomes. Summary effect sizes have been produced from random effects meta-analyses, fit using restricted-maximum likelihood, with the Knapp and Hartung (2003) adjustment applied.42 The results of these meta-analyses should be interpreted with caution with respect to the discussion around heterogeneity of methods, generally small sample sizes, and potential for publication bias. Model summaries, forest plots, and funnel plots are presented in Figure X. Pro Prospective power analyses were carried out to provide estimates of minimum required sample sizes with the jpower module (version 0.1.2, Morey & Selker, 2019)43 for Jamovi. A summary of prospective power analyses for all five outcomes is presented in Table 11.
In several papers, complete summary statistics (i.e., means, standard deviations) were not presented. WebPlotDigitizer 4.5 (Rohagti, 2021)44 was used to extract means and standard deviations from relevant figures (Figure 3, Figure 5, Seymour et al., 2002).6 Where medians were reported with inter-quartile range (Grantcharov, 2004, Figure 2 & WebPlotDigitizer; Larsen et al., 2009; Shore et al., 2016) ,9,25,35 means and standard deviations were estimated using the Box-Cox method described by McGrath et al. (2020; https://smcgrath.shinyapps.io/estmeansd/).45 Kurashima et al. (2014)36 reported median and range values and the quantile estimation method was used to estimate mean and standard deviation (McGrath et al., 2020).45 Gauger et al. (2010)28 did not report standard deviations for either group so pooled standard deviation was substituted based on Cohen’s d values and means reported in the paper. Coleman and Muller (2002) did not report any form of variance information in their paper and could not be included in the meta-analysis for Global Rating Scales.27
Random Effects Models
Error Rates
Observed standardized mean differences for error rates ranged from -2.45 to -1.09, with all estimates favouring fewer errors on average in the simulation groups versus controls. The estimated average standardized mean difference based on the random-effects model was = -1.38 (95% CI: -1.95 to -0.81) and differed significantly from zero (Figure XA), with evidence of little heterogeneity. Visual inspection of the funnel plot may suggest publication bias, supported by a significant Egger’s regression test.
Surgical Time
Observed standardized mean differences for surgical time ranged from -1.41 to -0.25, with all estimates favouring shorter surgical times on average in the simulation groups versus controls. The estimated average standardized mean difference based on the random-effects model was = 1.01 (95% CI: -1.43 to -0.58) and differed significantly from zero (Figure XB), with evidence of little heterogeneity. Visual inspection of the funnel plot may suggest publication bias, but Egger’s regression was non-significant.
Objective Structured Assessment of Technical Skills
Observed standardized mean differences for OSATS ranged from 0.36 to 1.31, with all studies favouring better OSATS outcomes in the simulation trained versus controls. The estimated average standardized mean difference based on the random-effects model was = 0.85 (95% CI: 0.34 to 1.37) and differed significantly from zero (Figure XC), with evidence of moderate heterogeneity of study effect sizes. Visual inspection of the funnel plot may suggest publication bias, but Egger’s regression was non-significant.
Global Rating Scales
Observed standardized mean differences for GRS ranged from 0.35 to 2.33, with all studies favouring better OSATS outcomes in the simulation trained versus controls. The estimated average standardized mean difference based on the random-effects model was = 1.35 (95% CI: -0.15 to 2.85) and did not differ significantly from zero (Figure XD), with evidence of moderate heterogeneity of study effect sizes. Visual inspection of the funnel plot suggests publication bias, which was supported by a significance Egger’s test.
GOALS
Observed standardized mean differences for GOALS ranged from 0.35 to 2.33, 1.07 to 1.42, with all studies reporting higher GOALS total scores in the simulation trained group compared to controls. The estimated average standardized mean difference based on the random-effects model was = 1.20 (95% CI: 0.92 to 1.48) and differed significantly from zero (Figure XE), with evidence of little heterogeneity. Visual inspection of the funnel plot may suggest publication bias, but Egger’s regression was non-significant.
Prospective Power Analyses
A full review of approaches to power analysis is beyond the scope of this paper but see the recent preprint from Lakens (2022) for pragmatic guidance.46 Using a data-driven approach, prospective power analyses were conducted for each outcome assessed. Minimum required sample sizes to achieve 80% and 90% power (α = .05, one-tailed) were calculated for a) the point estimate of the random effects model, and b) the lower bound of the 95% CI, or smallest observed effect size of the included studies if the random effect CIs crossed zero. In addition, the smallest reliably detectable effect for 80% and 90% power (α = .05, one-tailed) based on median sample sizes across included studies was calculated for each outcome to demonstrate the difference between current practice and what is needed to reliably detect effects of simulation training in future studies.
Sample sizes for most included studies were very small. Although observed effects were large in most cases, it is likely that these effects are inflated as a function of sampling error. The small number of studies in each analysis, alongside funnel plot distributions may suggest publication bias. The true effect of simulation training are likely to be over-estimated. One observation from table 1 is that the median sample size for three out of five studies falls below the minimum required sample size to reliably detect the point estimate with a minimum of 80% power. For lower bound estimates, reported median sample sizes fall between 1.78 and 13 times smaller than necessary to reliably detect those effects at 80% power, which rises to between 3.38 and 17.3 times smaller at 90% power, dependent on the outcomes. If publication bias is present, then even the lower bound estimates may be anti-conservative in some cases. Unless prospective studies adopt larger sample sizes, or engage with a priori rationale for sample sizes (cf. Lakens, 2022),46 opportunities for reliably identifying the benefit of simulation training may be missed, alongside opportunities for improving curricula and refining assessment methods.
__forest_plots_(middle)__a.png)
Discussion
Our aim was to carry out a systematic review of randomised trials to find out if such resource worthy simulation-based education leads to any benefits in actual real life surgical practice. Because of the rapid development and advancement in technology in simulation-based education in the present millennium, we decided to restrict our review to the published literature between 2000 and 2020. We excluded trials where participants were medical students because we wanted to include participants who were committed to a career in surgery and hence had the motivation and desire to improve and do better in their career.
Outcome measures
So many different outcome measures including the various scoring systems used by different authors makes it very difficult to carry out a meta-analysis and provide conclusive remarks on overall trends. Evaluation of skill levels and operative proficiency in the real-life operating room appears to be a major challenge in trials of this kind. Of all the outcome measures Global Assessment pf operative performance based on direct observation is said to have superior validity and reliability compared to evaluation with the help of check lists.47–50
Predominance of trials on laparoscopic procedure
It is obvious from the above-mentioned results of the included trials that SBT does indeed result in transfer of skills to real life practice in the operating room. Therefore, the efforts and resource spent in providin1g SBE in Surgical discipline appears justifiable.
It may not be altogether surprising for many readers to see that seventeen of the RCT s included in this review involved a laparoscopic surgical procedure.
The remaining two were trials on knee arthroscopy. Throughout the history of surgical training, the focal point of training has been the operating room. Laparoscopic surgery has become the gold standard for many abdominal surgical procedures.33 As a result, training in laparoscopic surgery has become a common subject of educational research in the field of surgical education. This is mainly due to the fact that learning the skills in laparoscopic surgery is relatively more difficult compared to traditional open surgical procedures because of loss of three-dimensional visualization, lack of tactile feedback and counterintuitive movements of instruments which are often inflexible. Therefore, the apprenticeship model of training doesn’t fully fit in to this kind of surgical training, which is best achieved outside the operating room, certainly at least during the majority of learning curve.
In the trials included here, there were wide variation in methods of simulation-based education, methods of intervention and assessment of performance to detect transfer of skills to real life practice.
Simulators
In the seven trials with laparoscopic cholecystectomy, Ahlberg et al,33 Gauger et al28 and Hogle et al32 used LapSim Virtual Reality for training their participants in the SBT group, Grantcharov9 and Seymour6 used Minimally Invasive Surgical Trainer – Virtual Reality (MIST-VR), Scott34 used a video trainer and Sroka38 used Fundamentals of laparoscopic surgery programme of the American College of Surgeons. For Trials on laparoscopic salpingectomy, four authors used four different kinds of simulators (Larsen,25 Coleman,27 Shore,35 Patel37). For laparoscopic bilateral tubal ligation Banks and Gala used a standard laparoscopic simulator produced by Limbs and Things, Bristol, UK.24,31
For their trials with knee arthroscopy, Cannon (2014)39 used ArthroSim Virtual Reality Simulator and Roberts (2019)40 used a dry knee arthroscopy model along with an American Board approved simulator. These simulators taught the skills that were needed by the novice learners to perform the required surgical procedure. In all the trials SBT was supervised by trainers who set proficiency targets to be achieved before the real-life surgical procedure was performed in the operating room. Simulators alone cannot provide a wholesome rounded training programme. Learners wanting to perform a procedure need to know, what to do and what not to do, how to do it and how to identify when they make an error. That is where lies the role of a good training supervisor who needs to know how the trainee is progressing and where in the learning curve the trainee’s ability is positioned and that training includes both psychomotor and cognitive learning. Unless simulators are integrated in an appropriately structured curriculum, their true potential may not be harnessed adequately. Nevertheless, use of various different types of simulators by trainers across the world makes it difficult to structure an agreed curriculum of uniform and satisfactory standard.
Assessment
In this systematic review we see large variation of methods or tools of assessment even for the same procedure. For laparoscopic cholecystectomy, Ahlberg used mean number of errors, surgical procedural duration and number of conversions from laparoscopic surgery to open procedure.33 For the same procedure Gauger (2010) used28 GOALS and average of total number of errors recorded by each assessor, Grantcharov (2004)9 used economy of movement, duration of procedure and an error score, Hogle (2009)32 used a 5-point Likert
GRS which assessed 7 aspects of surgical skills, Scott (2000)34 and Sroka (2010)38 used the similar GRS but devised by different authors, Reznick 199749 and Vassiliou 2005.51 Scott assessed the performance of the entire procedure of laparoscopic cholecystectomy.34 Grantcharov assessed the clipping and cutting portion of the procedure while Seymour assessed only the excision of gallbladder from the liver.9
For assessment of performance in knee arthroscopy, Cannon (2014)39 used procedural checklist, visualization scale, probing scale and global rating, whereas Roberts (2019)40 used wireless elbow worn motion sensors to objectively assess surgical performance metrics in addition to minor movements, smoothness and time taken.
However, despite these variations, the participants who underwent SBT before performing surgical procedure in real life patients in operating room performed significantly better than their colleagues who did not have SBT (Controls). The SBT group did not always show better performance in all aspects of assessment when compared to their counterpart Control group, but the fact is that the Control group never showed superiority over the SBT group.
Gallagher et al (2005)52 suggested that measurement of surgical error is the most valuable metrics that SBT can provide in the assessment of competence. Ahlberg et al (2007),33 Van Sickle et al (2008),30 Seymour et al (2002)6 and Grantcharov et al (2004)9 used error rates or error scores in their assessment of performance.
Amongst the nineteen trials included here, only one trial (Seymour et al 2002) mentioned instances of takeover by the attending surgeon.6 In this trail there were six such instances when the attending surgeon had to take over.
These were marked as ‘errors’ and occurred exclusively in the standard programmatic training group (Controls). No statistical significance was documented. These instances indicate a dangerous lack of competence or ability to operate and constitutes great risk to patient safety. Such failures are likely to be rooted in lack of competences which are beyond technical skills alone and may not be mastered by training on simulators alone. It is vitally important that surgeons acquire non-technical skills through structured training process which can then lead to enhanced patient safety.
Duration of training and time factor in assessment
In all the trials the SBT group were trained until they reached predefined targets or achieved proficiency levels set by the trialists. The time taken for such training varied. Assessment of proficiency was tested almost immediately after the completion of training. One author (Gala et al, 2013)31 reported that they found it difficult to facilitate the completion of their trial by many residents during a single rotational block and also because of the variation in the number of patients seeking the operation being tested which was sometimes worsened by last minute cancellation of operations. However, they did not find any statistically significant difference between their SBT and Control group. Whether the duration of training or the minimum number of cases or both are important criteria in determining transfer of skills seems to be uncertain although both parameters have its proponents (Casa, 1999; Strum et al, 2008).53,54
Brunner et al (2004), suggest that training programmes solely based on duration of training or number of repetitions may be inadequate for acquiring skills because learning curves vary and can be lengthy in novice learners.55
Some authors used surgical time or duration of procedure as outcome measures of proficiency.6,25,30,33,40 But Gauger et al (2010)28 feels that speed of operation is not an appropriate surrogate for proficiency-based training.
Limitations
The sample sizes in the included trials were mostly less than 25 participants in each trial. Only 5 of the trials recruited more participants of which 2 trials had 27 participants (Shore et al 2016)35 and 30 participants (Roberts et al,2019).40 This limitation was acknowledged by the respective authors and usually attributed to the limited number of post graduate resident trainees in the rotational training programme.
In nine of the nineteen trials, a statistical calculation for sample size and power was undertaken. In four of these nine trials, Gala et al 2013,31 Kurashima et al 2014,36 Roberts et al, 201940 and Scott et al, 2000,34 the number of participants who eventually completed the study fell short of the calculated sample size. In the trial by Kurashima et al (2011),56 the mean GOALS scores which formed the basis of power calculation was not achieved. In the remaining ten trials the authors did not declare any statistical calculation of power of study or sample size.
This objective of this systematic review was to find out skills transfer from the simulation-based training (SBT) to the real-life surgical procedure in operating room and as such trials included in this review were irrespective of patient outcome-based assessment or type of simulation used. Determinants of transfer of skill include design of simulator, functional capability of simulator, design of the training programme, preparation before SBT, nature and type of formative and summative feedback and opportunity for remedial or corrective measures to be taken for any shortcomings detected during SBT. This means that the evidence favouring transfer of skills should not be attributed to simulation alone.
Both the control group as well as the SBT group were undergoing on the job training as part of their residency programme and are likely to have encountered the same operation during their regular resident training. This kind of additional out-of-trial experience would have added to their resultant knowledge and skills which would be wrong to attribute to SBT only as part of the trial. In addition, there is the possibility of assessor bias regarding the abilities of the residents because the recruited residents were already working in the same institutions as part of their rotational training programme. This phenomenon might have affected the evaluation of trial participants and outcome of the trials.
Gala et al (2013)31 recruited the largest number of participants, that is 102, but unfortunately assessment of skills on laparoscopic bilateral tubal ligation was not a blinded process. The authors admit the unblinded design of the randomization assignment. They did try to mitigate for this by separating the SBT teachers from the surgical proctors and also asked the participants not to disclose their randomization to others. In another trial Hogle et al (2009)32 assessors evaluated operative skills of participants on elective laparoscopic cholecystectomy in an unblinded manner. Again, the authors admitted to this shortcoming.
The various different simulators, variety of assessment tools used, and different endpoints of training is likely to have led to inconsistencies in assessment making it difficult to make conclusive remarks on the skills achieved at the end of the training and the outcome of assessment.
In many of the trials, assessment and evaluation of competence was undertaken on video recordings of the operative procedure by trial participants. This is likely to have limited the capacity to extensively review errors because the field of view would be restricted to the field of operation and potentially exclude views outside the patient’s abdomen. Scott et al (2000)34 suggest that for assessment of differences in performance, direct observation is superior to video analysis.
Also, we don’t know how long the skills acquired from SBT lasts. Assessment of skills and proficiency on real life patients in the trials included here were undertaken within a very short time period of the SBT. Whether long term maintenance of such acquired skills requires regular ‘booster doses’ of SBT, remains unclear. Hence the transfer of skills from the SBT room to the real-life operating room might be a transient or temporary phenomenon.
Conclusion
The ultimate success of SBT depends transfer of skills from the simulated setting to real life operating rooms. The objectives of running a SBT course can be evaluated by application of Kirkpatrick levels 1, 2 and 3, namely: 1) reaction of the learner 2) learning by the learner 3) behavioural change.47 These Kirkpatrick levels are similar to phase 1 of evaluation strategy suggested in translational science research (TSR) method.48
For assessing the utility of SBT courses, Kirkpatrick’s levels and Translational Science Research framework are two practically useful frameworks. Their description are as follows.
Kirkpatrick level 1: Learner’s reaction to the process of learning. There is no corresponding phase for this stage of learning in TSR framework.
Kirkpatrick level 2: Degree or extent of enhancement of learner’s knowledge and skills. TSR phase 1 corresponds to this level and is demonstrated by learning in simulation course.
Kirkpatrick level 3: Skills transferred to capability to perform the practical procedure in real life job or clinical practice. TSR phase 2 equated to this level.
Kirkpatrick level 4: Influence or effect of the SBE course on patient safety. TSR phase 3 is equivalent to this level as it is used to demonstrate whether there was any significant improvement in outcome for patients as a result of the skills acquired in the SBE course.
At present we undertake evaluation of our course at Kirkpatrick levels 1, 2 and partially at level 3.
It may be inappropriate to draw firm and ultimate conclusions on the basis of this systematic review because of methodological inconsistency, differing types of simulation-based training, heterogeneity of outcome measures and possible publication bias for positive or significant trials only, and sample sizes that are likely to be too small to reliably detect realistic effect sizes. Patient outcome was assessed in only one trial and those outcomes were short term.
However, on balance of the available evidence, this review shows that mean error rate was significantly less in the SBT group when compared to the Control group. Mean surgical duration (time) was less in the SBT group when compared to the Control group. Mean OSATS score was higher in the SBT group when compared to the Control group indicating that the SBT group performed better than Controls. GRS score was higher in the SBT group when compared to Control group, suggesting improved skills in SBT group, but this betterment was not statistically significant. Global operative assessment of operative laparoscopic skills (GOALS) score was significantly better in the SBT group suggesting a clear improvement in skills in the SBT group. There appears to be publication bias in estimation of mean error rates and GRS scores.
Larger adequately powered trials should be carried out employing widely available standard simulation-based training, using well defined validated outcome measures, consistent techniques of assessment including assessment of both short- and long-term patient outcomes.